

{kind=link}
A distinct feature of poetry, which immediately distinguishes it from prose, is the use of spacing around the text of the poem. This wielding of whitespace - indentation, inline/staggered spaces, line/stanza breaks - is not merely a stylistic flair but an integral component of the poetic expression that influences the semantics of the poem and uniquely guides the reading experience.
Existing research [1] in the field of natural language processing points to the generative capabilities of LLMs in poetry. However, in this blog post, we specifically examine whether LLMs can handle whitespace. Towards this goal, we examine:
- What is the actual distribution of whitespace in existing poems?
- Can LLMs detect and classify enjambment in poetry?
- How do tokenizers affect whitespace in LLM-generated poetry?
- Future work ideas.
1. What is the actual distribution of whitespace in existing poems?
To answer this question, we use a dataset of 19,445 poems English poems by 4,330 poets from the non-profit Poetry Foundation.
In this dataset, 3240 poems were tagged with a "time period" to which they belonged (covering 315 poets) to enable a diachronic analyis of poems, as well.
| Time-Period | Pre-1550 | 1551-1780 | 1781-1900 | 1901-1940 | 1941-1970 | 1971-present |
|---|---|---|---|---|---|---|
| # Poems | 38 | 599 | 1205 | 949 | 340 | 109 |
| # Poets | 6 | 63 | 110 | 91 | 26 | 19 |
To analyse whitespace in particular, we represent poems as a sequence of whitespace and non-whitespace chunks, where we divide whitespace into two categories: inline whitespace (within a line) and line breaks (whitespace containing newline character). Further subcategories are as follows:
- Inline Whitespace:
- Single Space: exactly 1 space
- Multiple Inline Spaces: 2 or more consecutive spaces/tabs
- Non-Standard: any whitespace codepoint outside normal tabs, spaces
- Line Breaks:
- Minor Line Break: 1 or 2 newlines
- Major Line Break: 3 or more newlines
- Indented Line Break: any newline that is followed by whitespace
- Non-Standard: any whitespace codepoint outside newlines
1a. What is the distribution of whitespace in this dataset?
We plot the count of whitespace type across all poems in the dataset / time period. To visually account for the extremely high number of single spaces (as compared to other whitespace types, we plot the counts on the log scale instead).
Single space usage dominates any other whitespace type across all poems.
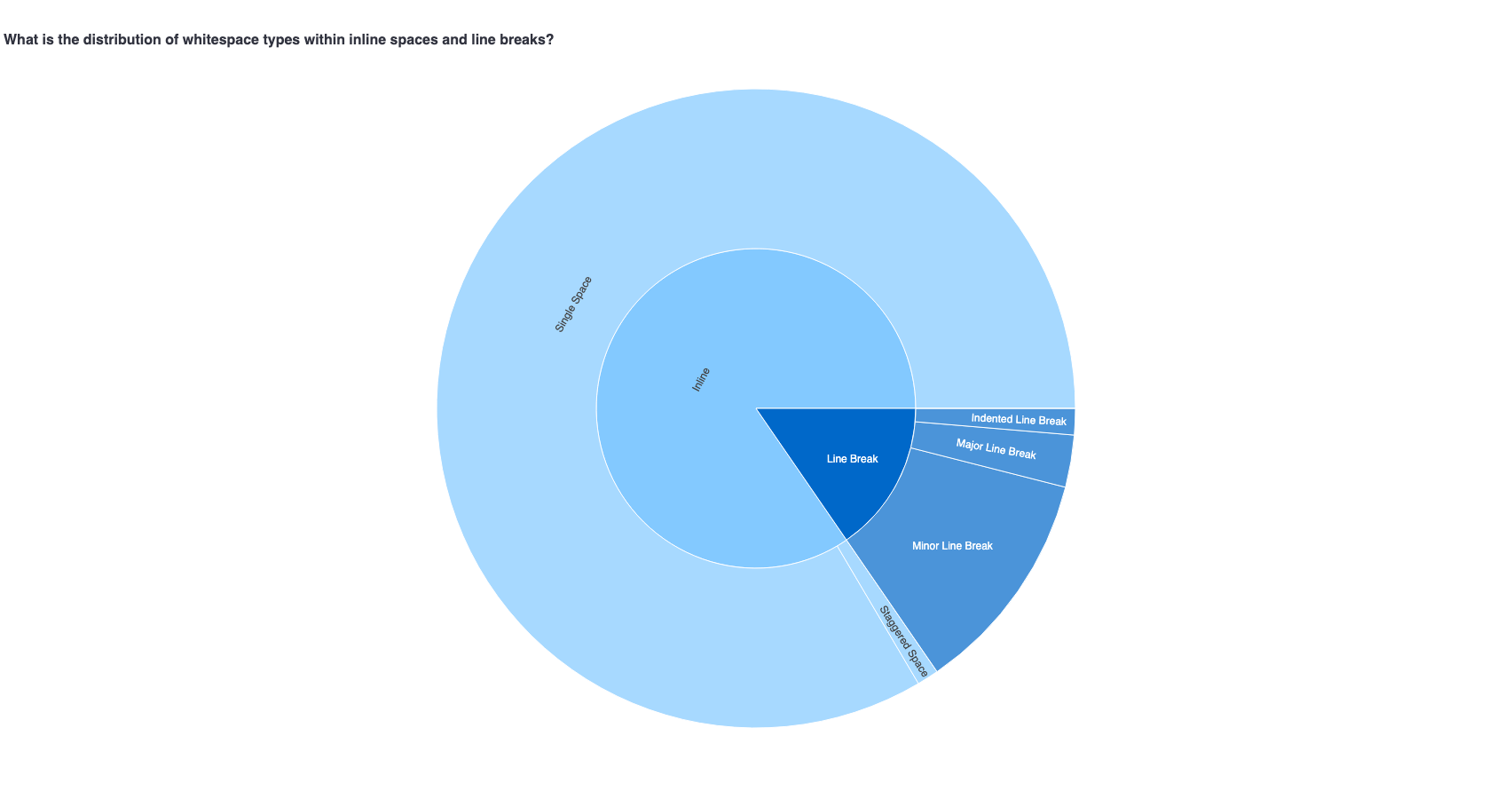
A time period based analysis of whitespace shows similar distribution of whitespace ratios for single space usage.
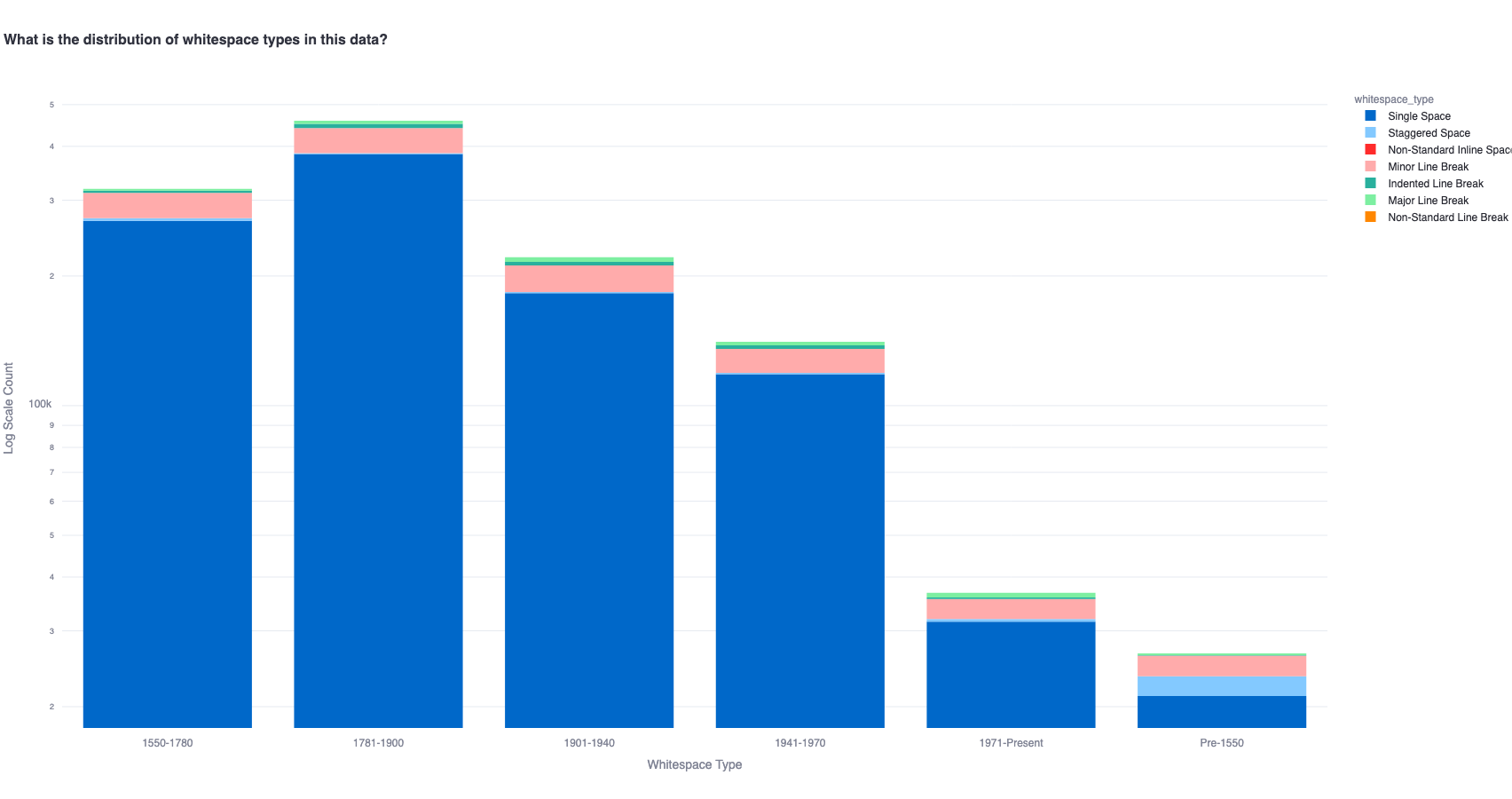
However, within non-single-space, the distributions vary across time.
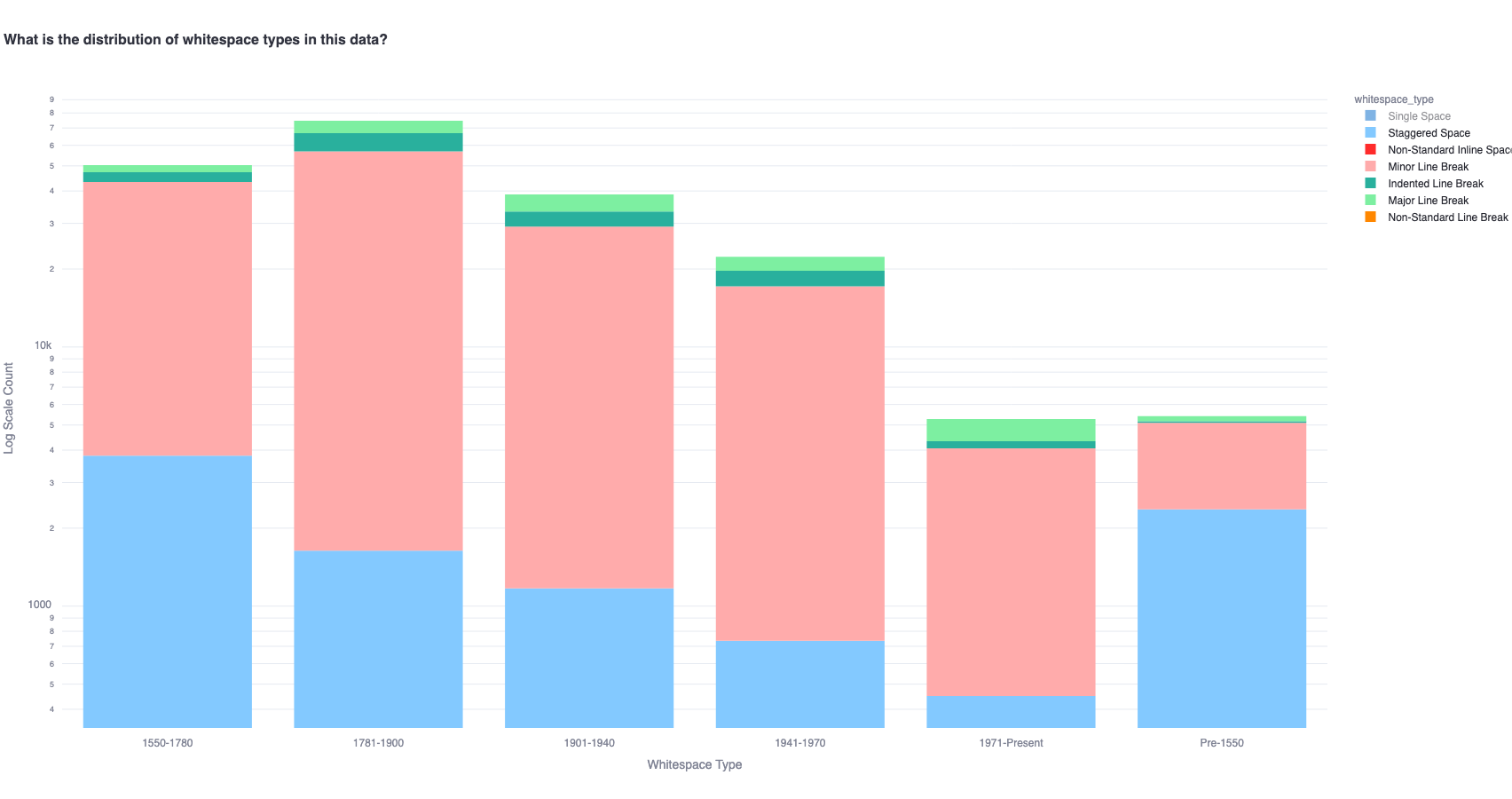
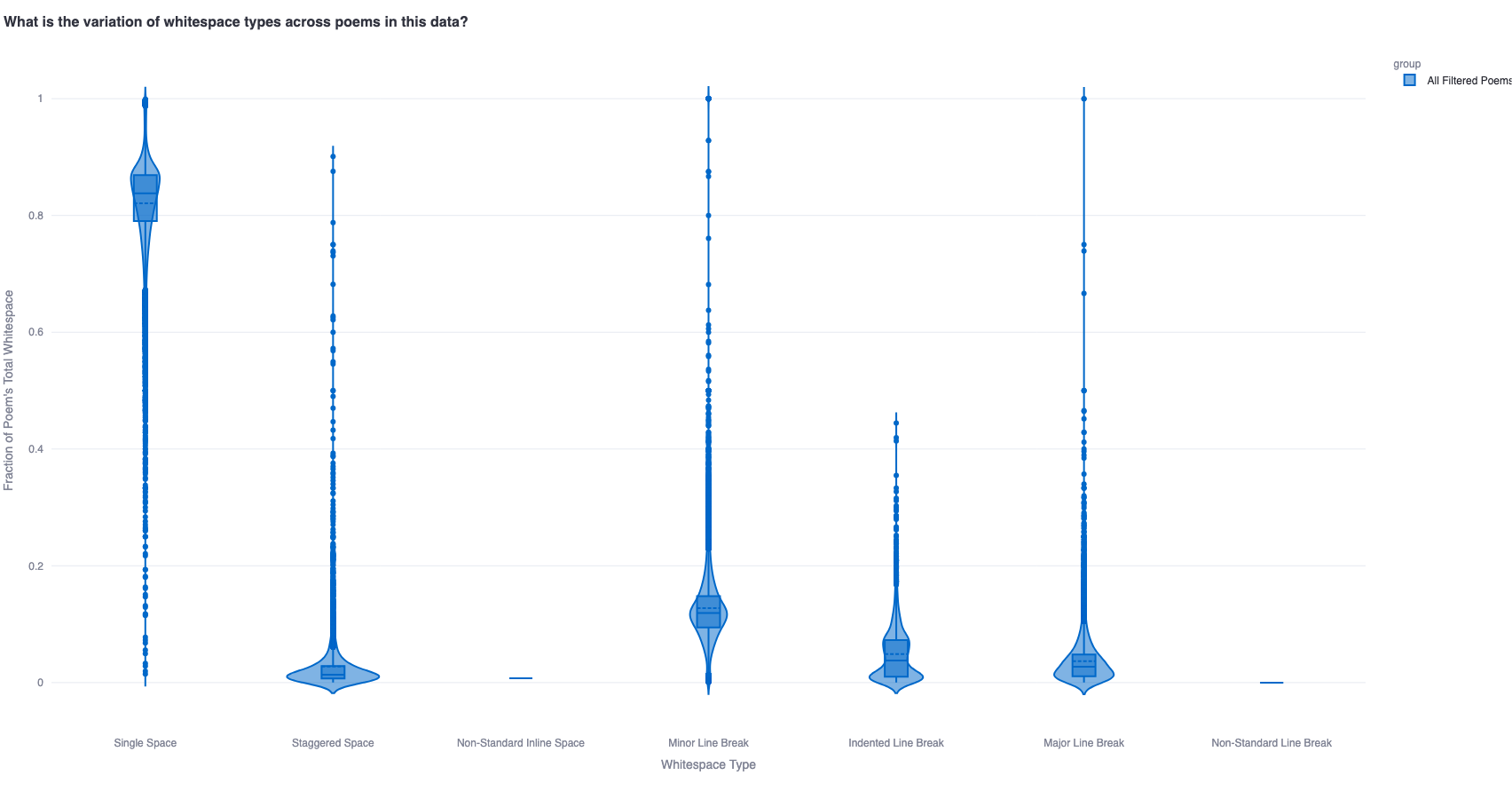
1b. What is the variation of whitespace usage across poems?
To measure this, we calculate the fraction of poems that uses a particular whitespace type - this helps compare poets'/eras' styles. For instance, we expect E.E. Cummings to have a more generous usage of whitespace (higher fraction of unconventional whitespace) than William Shakespeare.
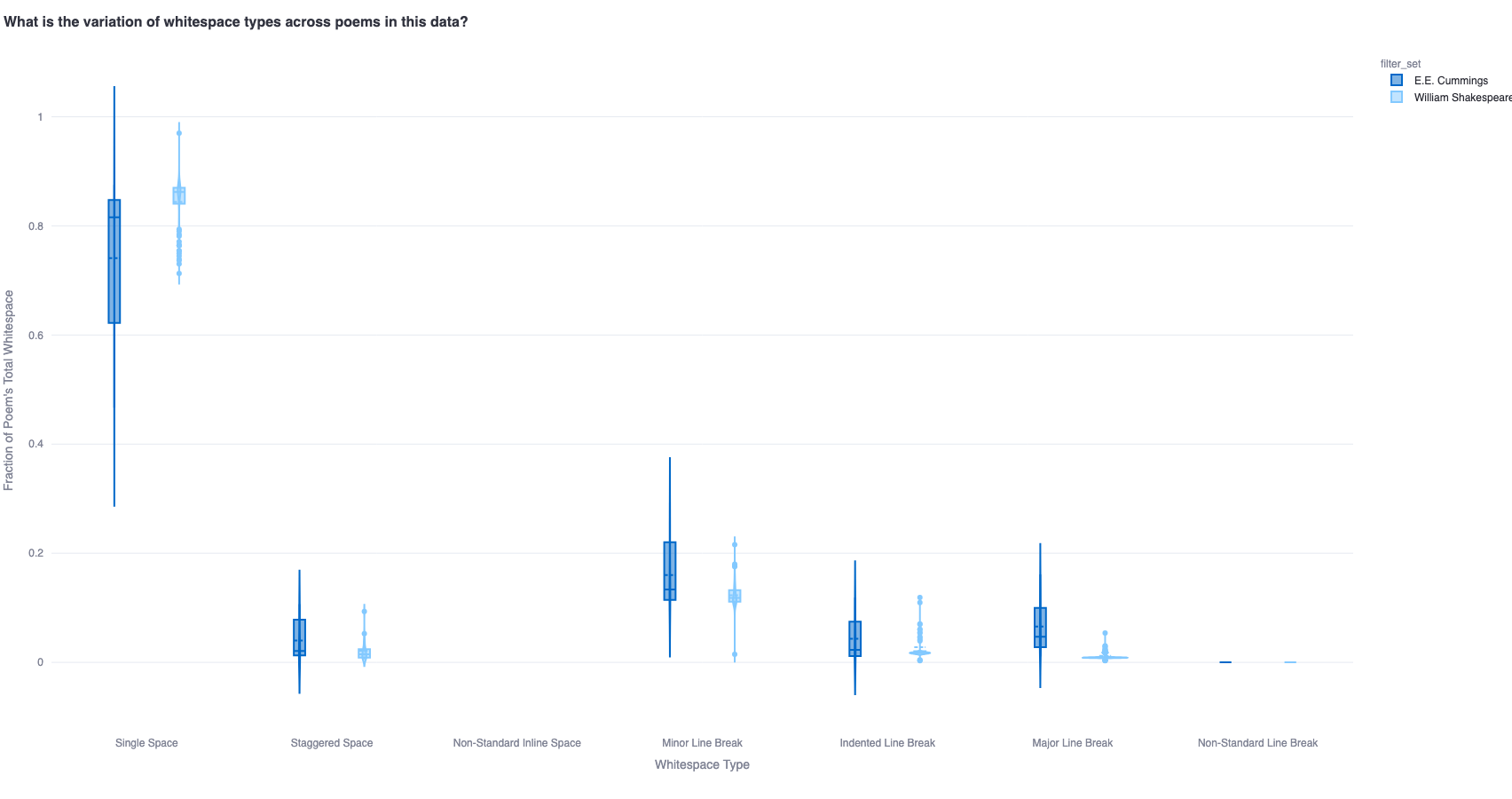
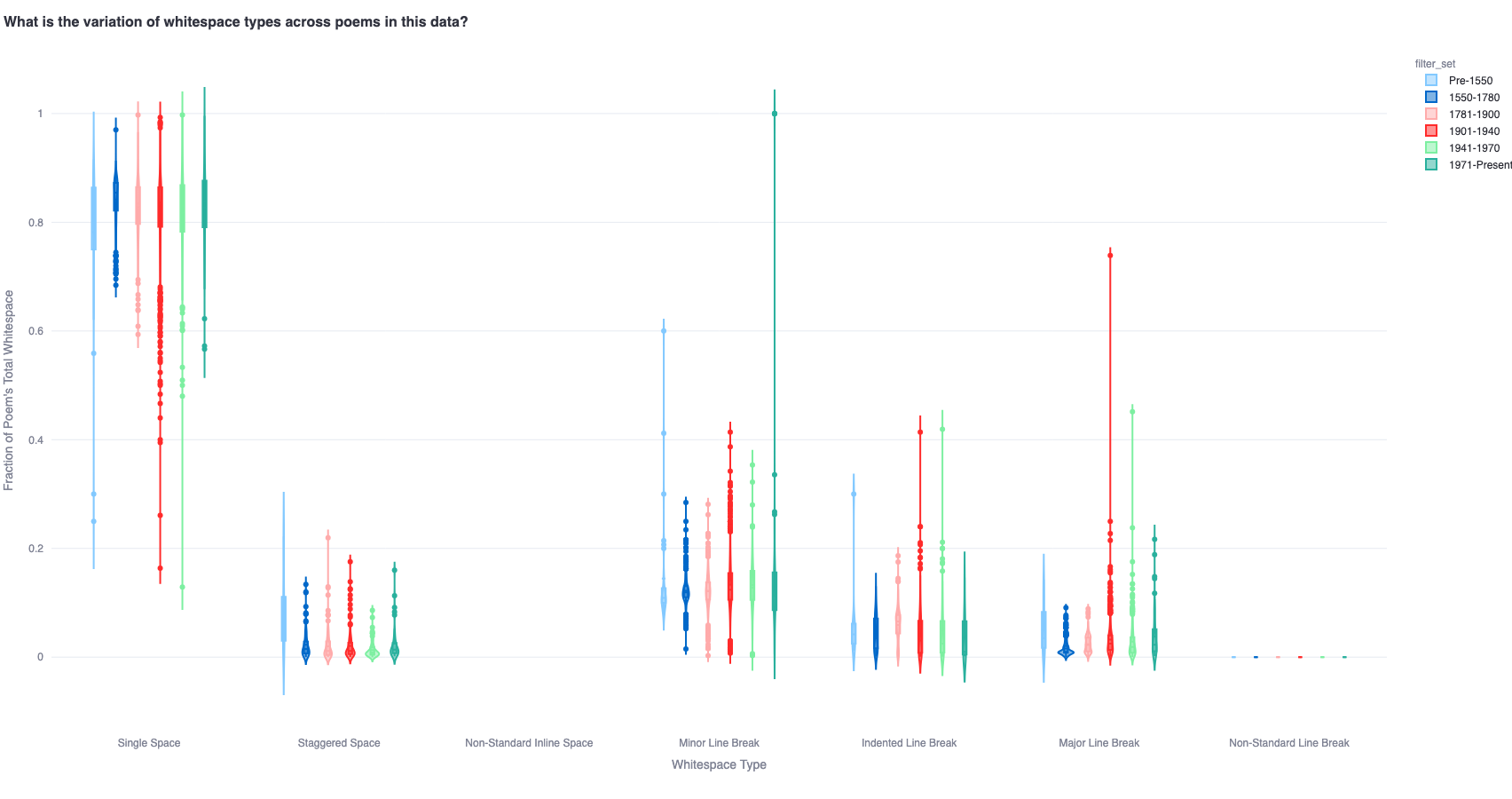
This fraction-based analysis of whitespace variation can be extended across multiple time periods as well - showing interesting trends across time which can be better contextualized against the variation across all poems as a benchmark.
1c. How has the relationship between line counts/lengths, and whitespace distribution changed across time?
Let's take a hypothesis - let's say poems with shorter lines (number of words per line) sometimes lend themselves to more variation with whitespace usage (staggered spaces, inline spaces). Or another hypothesis, which claims that poems with more lines lend themselves to more scope for whitespace variation. How can we confirm such hypotheses?
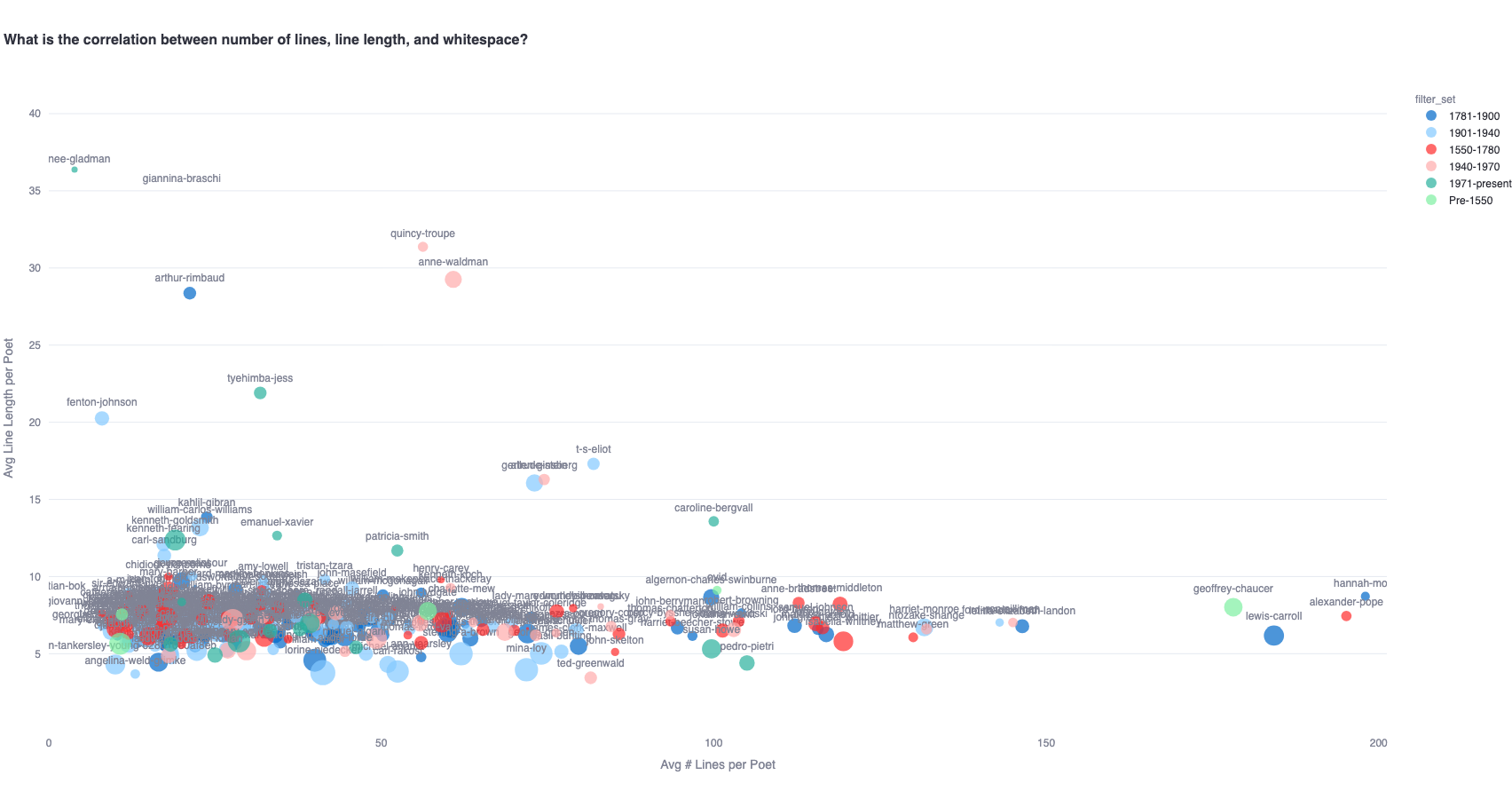
One approach can be to observe the relative presence of unconventional whitespace (whitespace that is neither a single-space nor a minor line break) across different line lengths/counts. To this effect, we plot a graph that represents poets' average number of lines per poem and average words per line on the x and y axes respectively, and average unconventional whitespace percentage per poem as the size of the bubbles.
Therefore, this is how we interpret the following graphs:
- Larger bubbles indicate that poets use more 'unconventional' whitespace on average per poem (smaller bubbles indicate that they are more 'conventional').
- Bubbles further to the right on the x-axis indicate poets with a higher line count average in their poems (bubbles to the left indicate poets with a lower line count average)
- Bubbles higher up on the y-axes indicate poets with higher average word count per line in their poems (bubbles relatively indicate poets with a low average word count per line in their poems).
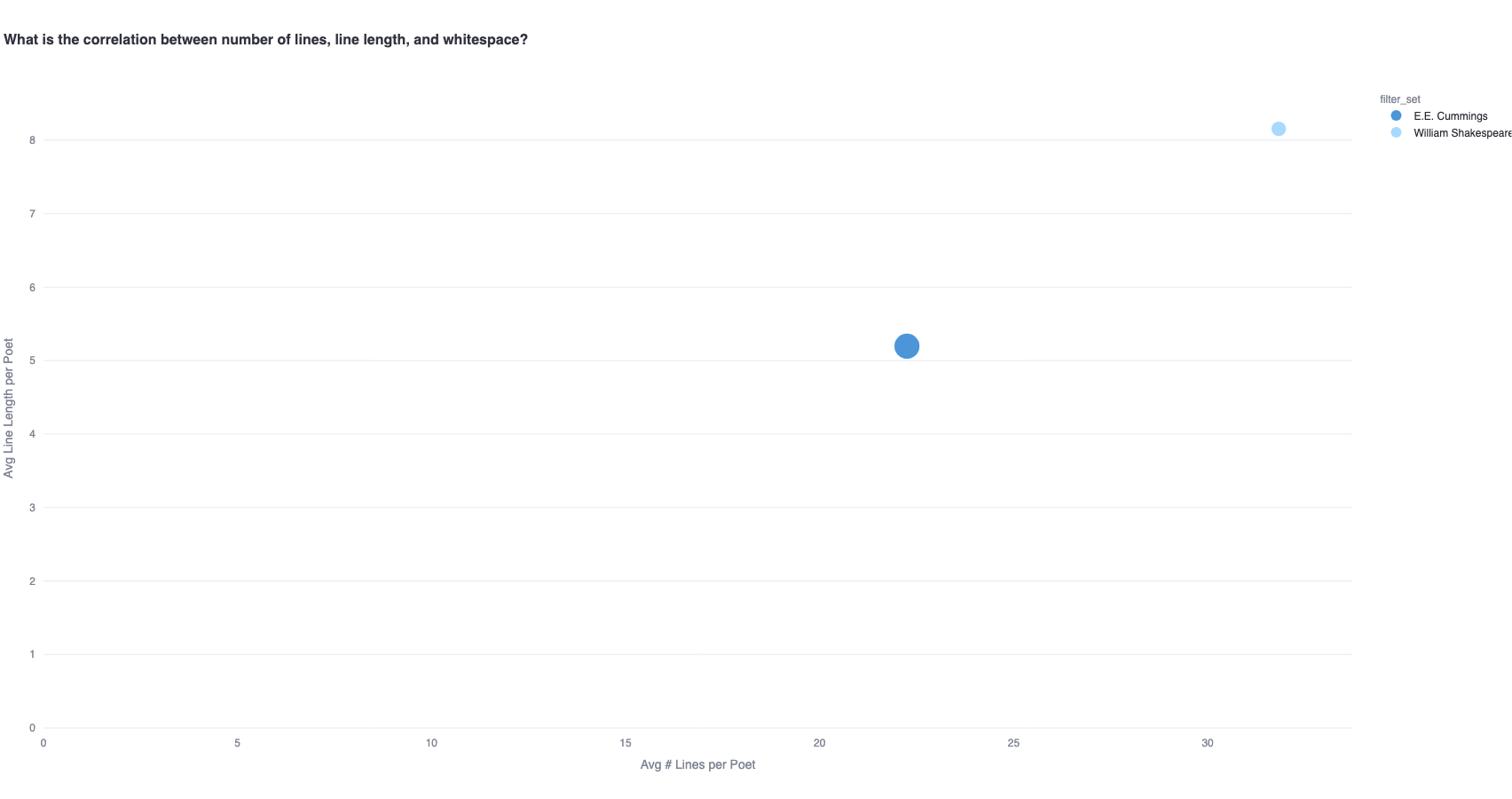
This graph, for instance, confirms that Cummings seems to have fewer lines per poem, and fewer words per line than Shakespeare, but a higher percentage of uncommon whitespace per poem on average.
A similar analysis can be conducted for a diachronic view of this relationship by plotting poets belonging to different time periods. The zoomed out view highlights the outliers.
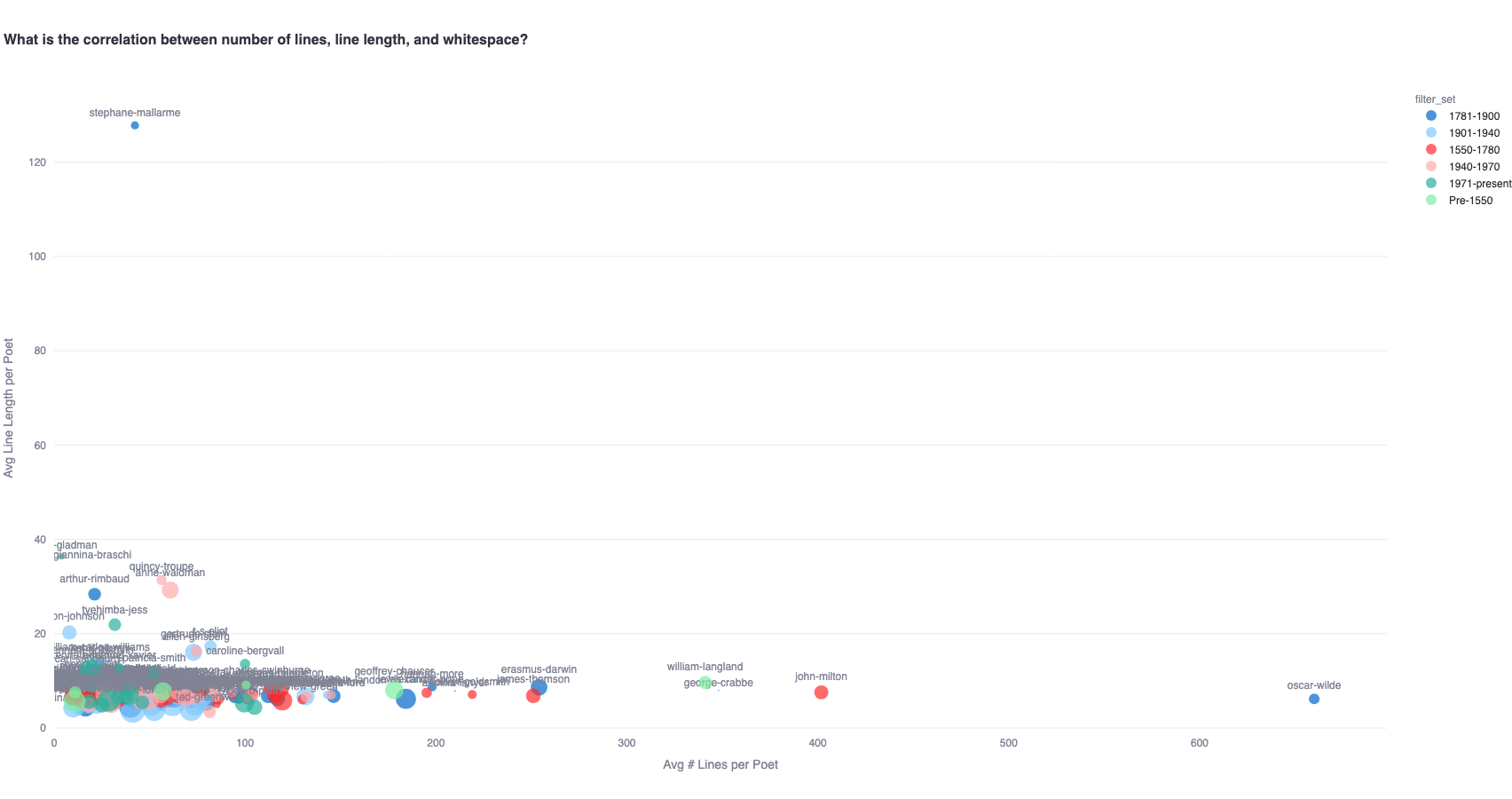
Zooming in to 40 line length / 200 line count cluster:
Or further to 20 line length / 100 line count cluster:
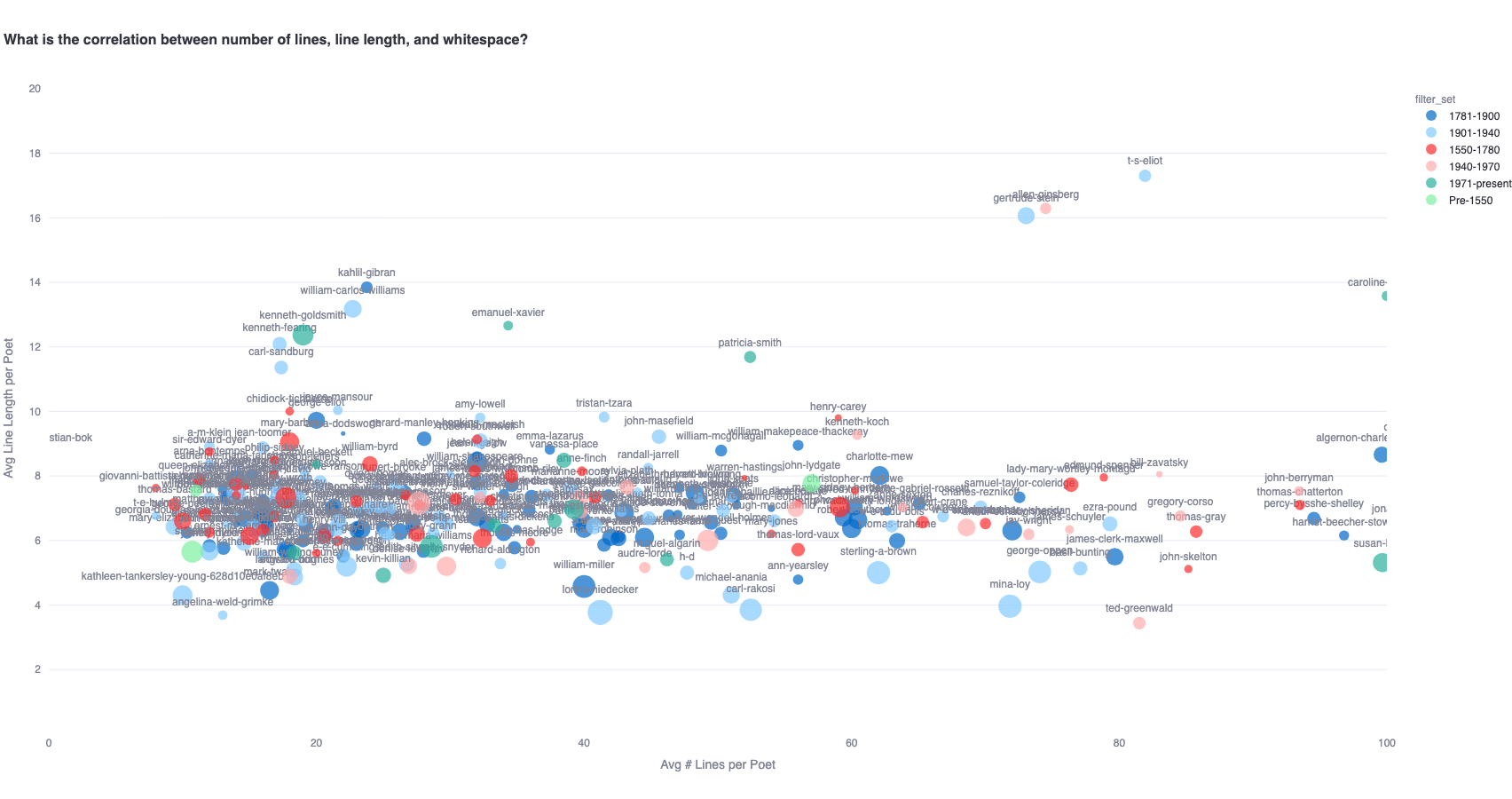
All these graphs help us quantitatively establish our premise of how whitespace distribution is an important stylistic feature of poetry. This paves the way for an investigation into how generative models like LLMs, which are trained on these poems in a for-profit setting (often without copyright considerations), handle whitespace.
2. Can LLMs detect and classify enjambment in poetry?
According to the Princeton Encyclopedia of Poetics, enjambment is defined as "The continuation of a syntactic unit from one line to the next without a major juncture or pause". This is made possible through the poet's artistic choice of deploying line breaks at specific locations in the text of the poem - the motivation behind this choice being unique to each school, movement, subculture, and time period of poetry.

One approach to investigate if LLMs capture whitespace in poetry is through the proxy means of using them to detect and classify enjambment. We
Detecting and Classifying Enjambment
We take inspiration from Ruiz Fabo et al's work [2] on enjambment detection in Spanish sonnets to define our typology for English. Specifically, we borrow the linguistic characterization from [3] and [4] to define three categories of enjambment: lexical, cross-clause, and phrase-bounded enjambment, where:
- Lexical: A word split across two lines,
- Cross-Clause: A noun and its modifying relative clause split across two lines,
- Phrase-bounded: Two strongly syntactically connected elements of the same phrase split across two lines
################################################################
DEFINING enjambment_typology
################################################################
{
"title": "Enjambment Typology",
"description": "JSON schema for classifying enjambment types based on Quilis (1964) and Spang (1983), with additions for end-stopped and none.",
"type": "object",
"properties": {
"line_ending_type": {
"type": "string",
"description": "Indicates how the line ends.",
"enum": [
"Enjambment", // Line break disrupts a syntactic unit.
"End-stopped", // Line break coincides with the end of a phrase or sentence.
"None" // No enjambment present.
]
},
"enjambment_type": {
"type": "string",
"description": "The main category of enjambment (if applicable).",
"enum": [
"Phrase-bounded enjambment", // Line break splits an atomic phrase.
"Lexical enjambment", // Line break splits a lexical unit / word.
"Cross-clause enjambment", // Line break separates a noun-antecedent from its relative clause.
"Expansion" // Line breaks separates a subject or object from its root verb.
],
"if": {
"properties": {
"line_ending_type": { "const": "Enjambment" }
}
},
"then": { "required": ["enjambment_type"] }
},
"phrase_bounded_subtype": {
"type": "string",
"description": "Sub-category for Phrase-bounded enjambment (if applicable).",
"enum": [
"noun + adjective", // Noun phrase, eg. red\wheelbarrow
"noun + prepositional phrase", // Noun phrase with a prepositional phrase. eg. the cat\in the hat
"verb + adverb", // Verb Phrase, eg. die\soon
"determiner/article + noun", // Noun phrase, eg. the\cat in the hat
"auxiliary verb + main verb", // Verb phrase, eg. will\go
"verb + direct object", // Verb phrase, eg. "He sang\nthe sun"
"verb + indirect object", // Verb phrase, eg. "He gave\nthem a grenade"
"preposition + object of preposition", // Prepositional phrase, eg. "He whistled\nin the dark"
"infinitive marker 'to' + verb", // infinitive phrase "to\nbe or not to be"
"adjective + complement", // adjectival phrase, "glad\nthat it's done"
"adverb + modifying phrase/clause", // adverbial phrase "quickly\nenough"
"participle + complement" //participal phrase "running\nquickly "
],
"if": {
"properties": {
"enjambment_type": { "const": "Phrase-bounded enjambment" }
}
},
"then": { "required": ["phrase_bounded_subtype"] }
},
"expansion_subtype": {
"type": "string",
"description": "Sub-category for Expansion (if applicable).",
"enum": [
"verb + subject", // Verb and its subject on different lines.
"verb + direct object" // Verb and its direct object on different lines.
],
"if": {
"properties": {
"enjambment_type": { "const": "Expansion" }
}
},
"then": { "required": ["expansion_subtype"] }
}
},
"required": ["line_ending_type"]
}
Instead of using the raw text of the poem, we use a linguistically enriched version where the poem is broken into a sequence of text and whitespace chunks with additional metadata for each:
################################################################
DEFINING poem_input
################################################################
...
{
"text": "We",
"ws": " ",
"line_break": false,
"text_upos": [
"PRON"
],
"text_xpos": [
"PRP"
],
"text_deprel": [
"nsubj"
],
"text_(sent_id, token_id)": [
"(2, 1)"
],
"text_feats": [
"Case=Nom|Number=Plur|Person=1|PronType=Prs"
],
"text_head": [
"3"
]
},
{
"text": "real",
"ws": " ",
"line_break": false,
"text_upos": [
"ADV"
],
"text_xpos": [
"RB"
],
"text_deprel": [
"advmod"
],
"text_(sent_id, token_id)": [
"(2, 2)"
],
"text_feats": [
"Degree=Pos"
],
"text_head": [
"3"
]
},
{
"text": "cool.",
"ws": " ",
"line_break": false,
"text_upos": [
"ADJ",
"PUNCT"
],
"text_xpos": [
"JJ",
"."
],
"text_deprel": [
"root",
"punct"
],
"text_(sent_id, token_id)": [
"(2, 3)",
"(2, 4)"
],
"text_feats": [
"Degree=Pos",
"_"
],
"text_head": [
"0",
"3"
]
},
{
"text": "We",
"ws": " \n\n ",
"line_break": true,
"text_upos": [
"PRON"
],
"text_xpos": [
"PRP"
],
"text_deprel": [
"nsubj"
],
"text_(sent_id, token_id)": [
"(3, 1)"
],
"text_feats": [
"Case=Nom|Number=Plur|Person=1|PronType=Prs"
],
"text_head": [
"2"
]
},
{
"text": "Left",
"ws": " ",
"line_break": false,
"text_upos": [
"VERB"
],
"text_xpos": [
"VBP"
],
"text_deprel": [
"root"
],
"text_(sent_id, token_id)": [
"(3, 2)"
],
"text_feats": [
"Mood=Ind|Number=Plur|Person=1|Tense=Pres|VerbForm=Fin"
],
"text_head": [
"0"
]
},
{
"text": "school.",
"ws": " ",
"line_break": false,
"text_upos": [
"NOUN",
"PUNCT"
],
"text_xpos": [
"NN",
"."
],
"text_deprel": [
"obj",
"punct"
],
"text_(sent_id, token_id)": [
"(3, 3)",
"(3, 4)"
],
"text_feats": [
"Number=Sing",
"_"
],
"text_head": [
"2",
"2"
]
},
...
We include this input version of the poem and the enjambment typology in a zero-shot prompt setting for enjambment classification with LLMs.
################################################################
DEFINING system_message
################################################################
system_message = """
You are a linguist who can use use knowledge of syntactic patterns
in poetry to answer technical questions about a poem in a structured manner.
"""
################################################################
DEFINING human_message
################################################################
human_message = """
TASK
-----
Given the ENRICHED_POEM_JSON that contains chunks of a poem, predict the correct LABEL OBJECT
for each chunk with line_break: True, and return it in OUTPUT_FORMAT.
ENRICHED_POEM_JSON
-----------------
This is a JSON object that contains an ordered list of chunk objects that make up the poem.
Each chunk object corresponds to a sequence of text and whitespace tokens
that make up the chunk, enriched with linguistic features as follows:
[
...
{
"text": # text tokens between whitespace characters,
"ws": # whitespace characters between text tokens,
"line_break": # bool: if this is True, then it is a line break
"text_upos": # list: of text tokens with their Universal POS tags,
"text_xpos": # list: of text tokens with their language-specific POS tags,
"text_deprel": # list: of text tokens with their dependency relations,
"text_(sent_id, token_id)": # list: of text tokens with their sentence and token ids,
"text_feats": # list: of text tokens with their morphological features,
"text_head": # list: of text tokens with their deprel head ids,
},
...
]
Make a prediction for each chunk with line_break: True, and return it in OUTPUT_FORMAT.
LABEL_OBJECT
-----------
$enjambment_typology$
OUTPUT_FORMAT
-------------
{
"line_1": {
"location" : index of line,
"labels": label_object,
"explanation": "...",
},
"line_2": {
"location" : index of line,
"labels": label_object,
"explanation": "..."
},
...
}
POEM_INPUT
----
$poem_input$
"""
This prompt is fed to an LLM, and the output is evaluated against the ground truth. For instance, here is the output from gpt-4o-mini:
################################################################
MODEL OUTPUT / ENJAMBMENT CLASSIFICATION
################################################################
{
"line_1": {
"location": 3,
"labels": {
"line_ending_type": "End-stopped"
},
"explanation": "The line ends with 'Players.' which is a complete noun phrase, suggesting that it is an end-stopped line."
},
"line_2": {
"location": 6,
"labels": {
"line_ending_type": "End-stopped"
},
"explanation": "The line ends with 'Shovel.' which is a complete noun phrase, suggesting that it is an end-stopped line."
},
"line_3": {
"location": 12,
"labels": {
"line_ending_type": "Enjambment",
"enjambment_type": "Phrase-bounded enjambment",
"phrase_bounded_subtype": "noun + verb"
},
"explanation": "The line break occurs after 'We' and before 'real cool.', where the subject is separated from its predicate, indicating phrase-bounded enjambment."
},
"line_4": {
"location": 18,
"labels": {
"line_ending_type": "Enjambment",
"enjambment_type": "Expansion",
"expansion_subtype": "verb + direct object"
},
"explanation": "The line break occurs after 'We' and before 'Left school.', separating the subject from its direct object."
},
"line_5": {
"location": 24,
"labels": {
"line_ending_type": "Enjambment",
"enjambment_type": "Expansion",
"expansion_subtype": "verb + direct object"
},
"explanation": "The line break occurs after 'We' and before 'Lurk late.', separating the subject from its verb."
},
"line_6": {
"location": 30,
"labels": {
"line_ending_type": "Enjambment",
"enjambment_type": "Expansion",
"expansion_subtype": "verb + direct object"
},
"explanation": "The line break occurs after 'We' and before 'Sing sin.', separating the subject from its verb."
},
"line_7": {
"location": 36,
"labels": {
"line_ending_type": "Enjambment",
"enjambment_type": "Expansion",
"expansion_subtype": "verb + direct object"
},
"explanation": "The line break occurs after 'We' and before 'Thin gin.', separating the subject from its verb."
},
"line_8": {
"location": 42,
"labels": {
"line_ending_type": "Enjambment",
"enjambment_type": "Expansion",
"expansion_subtype": "verb + direct object"
},
"explanation": "The line break occurs after 'We' and before 'Die soon.', separating the subject from its verb."
}
}
The results are not without errors - in the output mentioned above, Location 12 is entirely hallucinated, and the enjambment at We \ Jazz June is not captured. We wish to expand this experiment to cover a larger dataset of poems over a series of LLMs for an exhaustive analysis of the errors for a better understanding of where models succeed and fail.
3. How do tokenizers affect whitespace in LLM-generated poetry?
Before a model can interpret any input text, that text first has to be "tokenized." Tokenizers break up texts into words and other useful chunks of text, and there are many different ways of doing this. In the past, many tokenizers relied on whitespace exclusively to delineate tokens, but modern tokenizers, like those used by OpenAI and other companies, can't just throw away whitespace and other characters. For example, Python relies on whitespace to structure code, and since these models are often intended for use by software engineers, it's vital that the input tokens include whitespace.
In poetry, whitespace is perhaps the main distinguisher between poetry and prose. For models to understand and use whitespace appropriately in poetry, they would need to see accurate examples of whitespace usage in poems.So are the engineers scraping poems actually preserving whitespaces?
This process faces two big problems.
First, different websites can present the same poem with different whitespace usage. How are we to know which is canonical? If both are scraped and used as training data, what happens to the model's output?
Second, after scraping data, the scraped HTML needs to be transformed into text that can be used by the tokenizer. Different tools can be used for this transformation, and each tool can output different results. We've tested a series of different tools on poetry, and we've found significant differences in how whitespace is handled. This results in tokenizer inputs with different whitespace usage, even for the exact same poem scraped from the exact same website.
This all leads us to some big questions about poetry and language models.
- This all leads us to some big questions about pretraining data, inspired by poetry.
- What kinds of technical choices were made during data scraping?
- What kinds of domain and curation choices were made?
- How does all of this shape model capabilities, as well model biases and alignment?
- And finally but also most importantly, what impact might downstream tasks have on upstream sustainability? How does taking data from creators impact their work, perhaps altering or destroying the creative work that made the model possible in the first place?